Deep Compression
Summary on "Deep Compression : Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding"
1. Problem
- Neural Net : Computationally intensive and memory intensive- Making them difficult to deploy on embedded systems with limited hardware resources
2. Solution
- Reduce the storage requirement of neural net without affecting accuracy by 35~49 X3. How
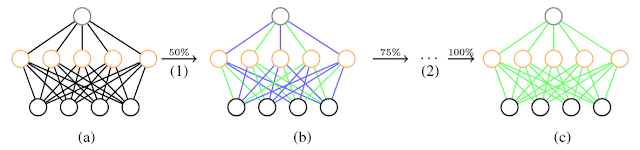
- 3 stage pipeline
1) Pruning
- By learning only the important connections, Prune the network- Reduce the number of connections by 9~13 X
2) Trained Quantization
- Quantize the weights to enforce weight sharing- Reduce the number of bits that represent each connection from 23 to 5
3) Huffman Coding
- Apply Huffman Coding4. Performance
- ImageNet+ AlexNet : Reduce the storage requirement by 35 X from 240MB to 6.9MB w/ loss of accuracy
+ VGG-16 : 522MB to 11.3MB

댓글
댓글 쓰기